
The EU General Data Protection Regulation (GDPR) comes into effect in May of 2018 and businesses who collect, use, and share data from European citizens – whether based in the EU or not – will have to comply or risk some pretty heavy punishment (up to EUR20m or 4% of annual worldwide turnover!). So how can the GDPR affect companies current processes when copying and moving data into non-production environments?
For every production system there can be tens of non-production database copies used to support the ongoing development and testing of that production system. In my 15+ years of working with databases in various industries I have rarely seen effective and secure processes to desensitize data when copying the production source to these supporting environments. To be fair, recent years have shown an improvement here but seldom enough and often the process is more of a token gesture to put a tick in a box, rather than a clear concerted effort to ensure the data is completely desensitized and importantly, certified to be so. That can’t be the case anymore.
Lets take a look at what impact GDPR has on this process and how the Delphix Dynamic Data Platform is a good example of a tool businesses can use to achieve compliance.
Pseudonymization Versus Anonymization
These are two distinct terms used in the context of data security and should be thoroughly understood by anyone dealing with the subject. It is especially important when dealing with GDPR because they are treated differently by the regulation. Briefly, anonymization destroys sensitive data irreversibly so that there is no way the data subject can be identified, either directly or indirectly. Pseudonymization substitutes sensitive data where additional data would need to be available to identify the data subject.
Where data is truly anonymized the data protection rules are not a concern. No identifiable data = no GDPR. However the data protection rules are a concern for pseudonymized data. Article 32 paragraph 1 of the regulation states “[companies] shall implement appropriate technical and organisational measures . . . [such as] the pseudonymisation and encryption of personal data”. The article goes on to state “Adherence to an approved code of conduct . . . or an approved certification mechanism . . . may be used as an element by which to demonstrate compliance with the requirements set out in paragraph 1 of this Article”
So the regulation wording specifically calls out the need for pseudonymisation and also calls for some sort of certification to show the data is truly desensitized.
Understand your data requirements
Before looking at how to anonymize or pseudonymize the data it is necessary to understand what the data requirements actually are in the non-production environment.
Some environments really don’t need any identifiable data within them. Some types of development environment are a good example. If I am developing a new application feature I don’t need real data to code it up and do initial functional tests. I would go as far as to say I don’t need a data copy of the source database at all, I just need the schema. In this case, the ultimate anonymization would be to truncate all tables where sensitive data exists and insert some fictitious data. Or just copy the empty schema alone. Simple.
Of course there are many cases where we do need real data. Lets take integration and performance test environments as an example. Without running these tests against real data we run the risk of hitting data related issues further along the process and in fact that can be as late as when the code is promoted to production. We could see failures due to unexpected data values/types or performance problems because we didn’t test against real data volumes and distributions. Now we have unhappy users and a service owner on the warpath!
Implementing *onymization
Whether it is anonymization or pseudonymization of the non-production data required, we want a process that is efficient, repeatable and automated. Extreme anonymization like I describe above is easily achieved with some simple scripts but where we want real and useful data (and comply with GDPR) we want a tool that can make it as quick and easy as possible. Also, it is not just the act of data masking we should think of. If there are ten non-prod databases to mask we need to run the process on each and every copy, which takes extra time and effort.
Delphix Data Masking can take care of all the anonymization and psuedonimization requirements and when coupled with Delphix virtualization we have a powerful feature rich platform to do it quickly and efficiently, over and over. Let’s take a look at an example workflow of provisioning a masked copy of a production database to a non-production environment using Delphix.
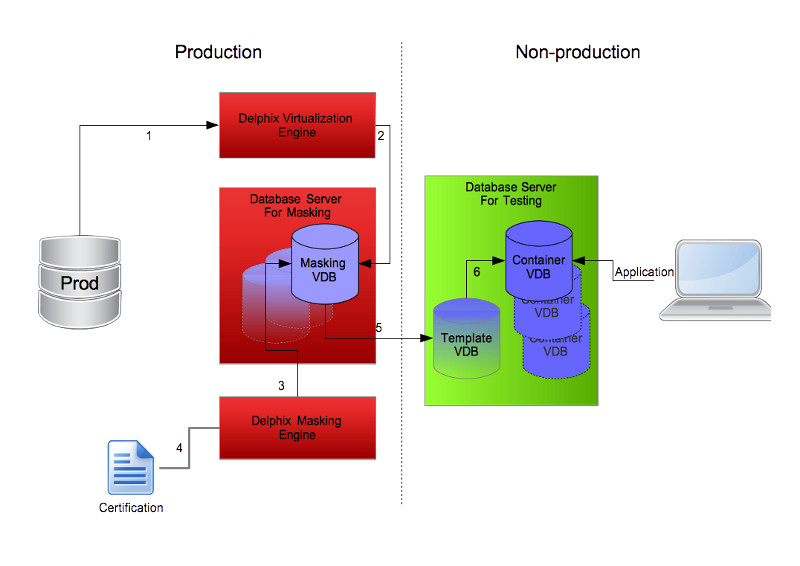
What we see above is a simple diagram we can follow to understand the process and importantly, a process that ticks many of the GDPR compliance boxes.
Production Side
On the production side of the diagram we ensure we follow standard design and process for production data including server hardening, access controls, firewall rules, etc. This ensures we can have production data in its original form on this side. It may even be a separate data centre to the non-production side (although in that case we would need another Delphix engine in the non-production data centre for replication).
The production side steps are:
1 – Create a dSource in the production Delphix virtualization engine and continuously sync from the production database.
2 – Provision a VDB on a productionised database server where we perform data masking. This server can be hosted within the same virtual environment as the Delphix engine and should be used only for data masking.
3 – Data masking is performed against the masking VDB using a production Delphix masking engine.
4 – A certification job is executed by the masking engine.
Non-production Side
The non-production side is where we host all the supporting environments such as development and test. The controls on this side are inherently more loose than production and therefore any sensitive data cannot exist in its original form.
The non-production side steps are:
5 – Once the masking VDB has been satisfactorily masked and certified we can provision a new child VDB (using the masking VDB as a parent) to a server on the non-production side. The example I am using here assumes the test team are utilising Delphix Self-Service (formally Jet Stream) and therefore this VDB should be a template source. A further word on that in a moment.
6 – Finally we provision a VDB to be the Self-Service container source, which becomes the VDB the end user (tester in this case) consumes and the test client application connects to.
Step 6 is where huge amounts of time can be saved because we have the ability to provision multiple copies of the masked VDB. Just a few a clicks and each provision process takes just minutes.
A note on Step 5 – This step depends on how we implement the masking process, which might or might not result in being able to use the masking VDB as a template source. Let me explain.
With Delphix Self-Service the end user can refresh their container VDB at any time and the source of data for the refresh is always the template. Whenever the end user needs fresh data (from production) then the masking VDB must be refreshed and re-masked first. It’s possible to configure the masking VDB to automatically run the masking process whenever it is refreshed so in this case there wouldn’t be a problem with the masking VDB being the template source. However, if the masking process consists of many individual jobs that need to run in parallel (to speed up the process) then we can not configure it this way – currently Delphix is limited to assign masking jobs serially only. Therefore, if the masking VDB was the template source then there is a chance the end user could perform a refresh before the refreshed masking VDB is masked and end up with production data.
That was probably a little hard to follow but in summary, if at any time the masking VDB is in a usable state with unmasked data then it should not be a template source. This way we ensure the end user cannot accidentally refresh their container and receive unmasked data.
Automation
Delphix offers the feature of configuring VDB refresh jobs according to a schedule. Where we can configure the masking VDB to automatically perform masking jobs as part of its refresh, the result is a fully automated pipeline providing pseudonymized (or anonymized) current data to the end user. This can all be configured through the Management and Masking GUIs.
If, like I mentioned earlier, we need to run multiple parallel masking jobs then we can still achieve an automated pipeline but we will need to utilize the Delphix APIs to script it up instead.
We now know the high level flow of provisioning desensitized data environments into non-production using Delphix and have a GDPR compliant process. But we still need to understand how we achieve GDPR compliant data so we need to look in more detail at the Delphix masking process itself (step 3 and 4 above) and see what the possibilities are to make it as easy and efficient as possible. I feel I should explore this in a separate post as it is not necessarily associated with GDPR and is a useful thing to understand in isolation. Stay tuned.

Matt is a technology consultant with over 20 years experience helping organisations around the world achieve data success using proven and emerging technologies. He is the Principal Consultant and Head Trainer at Kuzo Data.
Connect with Matt on LinkedIn.