
Faults in the Delphix virtualisation engine are automatically generated when a problem occurs and generally mean something is broken. They will be categorised as WARNING or CRITICAL and require some human intervention to fix.
When a fault occurs the GUI will show a red ‘Fault’ link in the top right part of the screen.

Clicking the link will open a small window where you can browse each active fault and further Ignore or Resolve them, or even Mark All Resolved. But when should you ignore a fault, when should you resolve a fault and when should you resolve ALL the faults, and what are you actually doing by ignoring and resolving?
It’s easy to misunderstand the concepts behind fault resolution and mistakenly ignore faults that should be resolved and vice versa, and even resolve all when you only want to resolve one, the carpet bomb approach you might say! So this post is to ensure you don’t make those mistakes.
To be fair, the words do describe the action pretty accurately according to the Free Dictionary:
- Resolve – to find a solution to.
- Ignore – to take no notice of; to pay no attention to.
We have a fault, let’s say the source database user account has been locked so the engine can not communicate with the source database now. The correct course of action here is to unlock the database account, check the Delphix engine can once again communicate and then resolve the fault. Easy. In this case I don’t think you would mistakenly mark the fault as Ignored.
We have another fault, Logsync on an Oracle dSource has failed to fetch an archivelog so now we can’t provision from this time period.
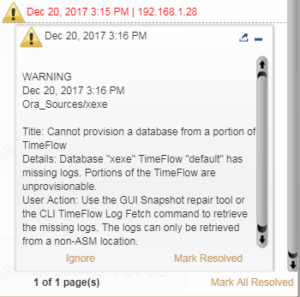
Our course of action here could be that we know we won’t need to provision from this time period so we don’t bother fetching the missing archivelog (repairing the Timeflow) and we mark the fault as Ignored. Wrong!
What we’ve actually done here is told the Delphix engine to not notify us of this fault ever again. Ever. Period. This is not good. No doubt the next time it occurs we DO want to know about it so we can actually repair the timeflow and ensure we can provision/refresh from this period of time.
The official docs do state this quite well:
You can mark the fault as Ignored if it meets the following criteria:
The fault is caused by a well-understood issue that cannot be changed
Its impact to the Delphix Engine is well understood and acceptable
In this case, the fault will not be re-diagnosed even if the fault condition persists. You will receive no further notifications.
We all make mistakes and like me, you may have ignored a fault when you should have resolved it but don’t panic, there’s a way to fix it. We can’t do it via the GUI so we have to drop into the CLI for this.
Go to the Fault context and list all faults
KDVDXE002 fault> ls Objects REFERENCE STATUS DATEDIAGNOSED TARGETNAME TITLE FAULT-12 IGNORED 2017-12-20T15:37:57.540Z Ora_Sources/xexe Cannot provision a database from a portion of TimeFlow ...
Select the Ignored fault and change it to Resolved
KDVDXE002 fault> select FAULT-12
KDVDXE002 fault 'FAULT-12'> ls
Properties
type: Fault
action: Use the CLI TimeFlow Log Fetch command to retrieve the missing log. The log can only be retrieved from a non-ASM location.
bundleID: fault.oracle.linkedsource.notprovisionable.timeflow.failedlogs
dateDiagnosed: 2017-12-20T15:37:57.540Z
dateResolved: 2017-12-20T15:38:43.083Z
description: Database "xexe" TimeFlow "default" is missing log sequence 1.129 because LogSync failed to fetch it more than 3 times.
reference: FAULT-12
resolutionComments:
severity: WARNING
status: IGNORED
target: default
targetName: Ora_Sources/xexe
targetObjectType: OracleTimeflow
title: Cannot provision a database from a portion of TimeFlow
Operations
resolve
KDVDXE002 fault 'FAULT-12'> resolve
KDVDXE002 fault 'FAULT-12' resolve *> commit
See the fault is now Resolved (not Ignored)
KDVDXE002 fault> ls Objects REFERENCE STATUS DATEDIAGNOSED TARGETNAME TITLE FAULT-12 RESOLVED 2017-12-20T15:37:57.540Z Ora_Sources/xexe Cannot provision a database from a portion of TimeFlow ...
So what have we done here? There is no way to set an Ignored fault back to active again so instead we set it to Resolved. Now the fault will pop up when the issue reoccurs. Not ideal but better than being stuck in the Ignored state.
Once last thing, the Mark All Resolved option
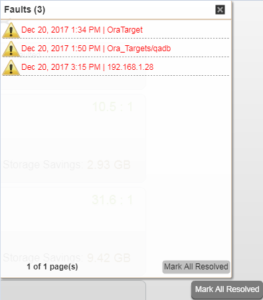
I sort of understand why this option is available. Maybe while we’re setting up the environment we generate lots of faults and once we’ve completed the setup we want to quickly resolve them all and start with a clean slate. Great, hit the “Mark All Resolved” button.
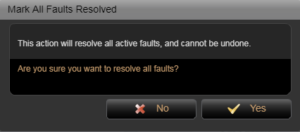
But my reason for mentioning this option is as a warning. Be careful with it. Apart from the scenario above I really can’t see a reason to ever use it. If this is a shared engine, and by that I mean shared amongst many teams each with their own environments hosted, then if we resolve all they may not know there has been a fault with their environment. Well, at least until it occurs again.
I hope this post at least makes you think twice before dealing with faults so they are dealt with in the right way. Just be careful of hitting Ignore when you are most likely intending to Resolve.

Matt is a technology consultant with over 20 years experience helping organisations around the world achieve data success using proven and emerging technologies. He is the Principal Consultant and Head Trainer at Kuzo Data.
Connect with Matt on LinkedIn.