
One of the key features of the Delphix Dynamic Data Platform is the ability, for the data consumer (Developer, Tester, QA’er, Data Analyst), to self serve data in an extremely functional and intuitive way. Operations like refresh, rewind, bookmark, branch and share at the touch of a button provide the end user unprecedented speed and agility while working with the data they need, and without raising tickets and bothering the DBA’s and Sys Admins in the process. Win win!
However, to take advantage of these rich features the Self-Service environment must first be configured by the Delphix Administrator and there are a some things to consider up front to ensure the Consumer get’s the data they want when they want.
Self-Service Concepts
Let’s have a quick reminder of the design concepts of Delphix Self-Service. There are two parts that make up a Self-Service environment – Templates and Containers.
A container is what the data user works with. It’s their datapod, which could be a single database, or a mixture of application files and multiple databases (check out the Self Service Data post for a demo of a database and file container). The operations performed in Self-Service by the data user act upon all data sources within their container.
A template is the backbone of a data container. It is the parent of the container and there can be a one-to-many relationship (and often is) – one template, many containers.
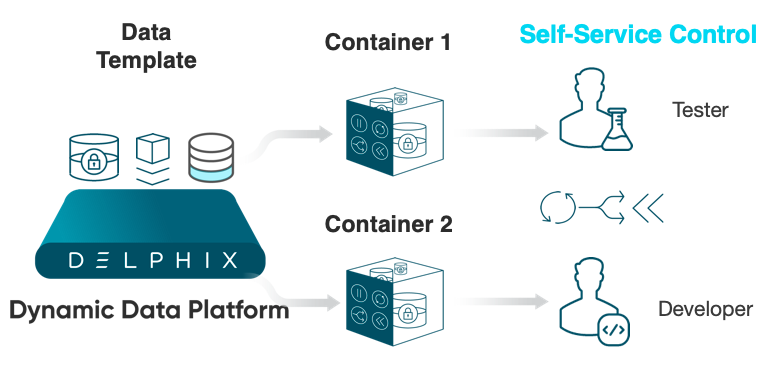
Templates and containers must be associated with data sources (dSources, VDBs, vFiles) and as implied, the container source must be a child of the template source (because the template is the parent of the container).
So before we go ahead and create Self-Service templates and containers we must first understand what the data user wants from their data and create the data sources accordingly.
Use Cases
There are numerous use cases for the Delphix DDP and Self-Service and I see new ones popping up quite regularly, although they tend to be variations or extensions of the more commonly known ones. For Self-Service, the main three are:
- Application Development
- Application Testing
- Data Analytics
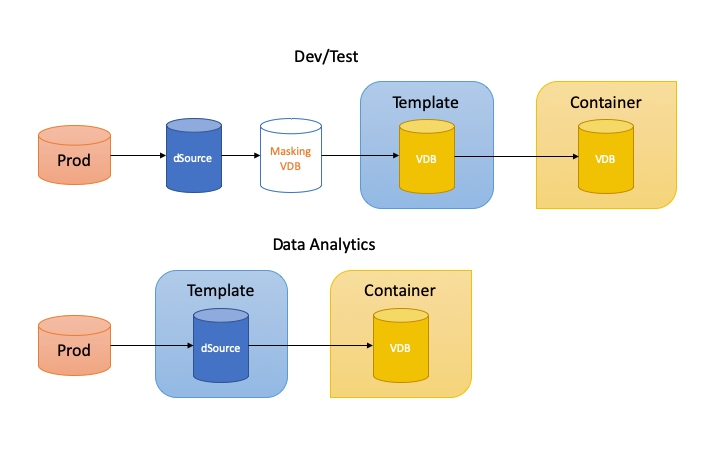
For the purpose of this post I want to show the difference in how we can configure Self-Service for application dev/test and data analytics. Specifically the difference in using a VDB or a dSource as the template source.
Template Source
It’s all about the template source! This is the most important thing to get right and that’s why I say we need to put some thought into it before we race ahead and create the Self-Service configuration. Remember, the end users datapod is their container. All the data they have comes from its parent, the template. In other words, when they refresh their container they make their data look like a copy of the template data sources.
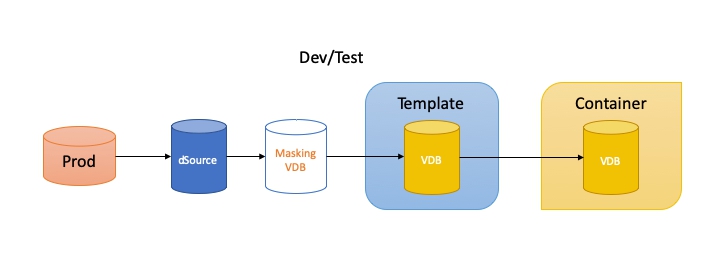
Application Dev/Test
For application development and testing the aim is to provide the dev/tester with a virtual database (VDB) they can immediately utilise with no worries about sensitive data.
The dSource that their VDB is created from is most often a copy of production with production accounts/passwords and obviously sensitive data. Therefore we must mask the data first (using Delphix masking) and add new user accounts with known passwords and possibly change some passwords of existing accounts. This allows the dev to access their VDB as soon as it is created or refreshed with their known credentials and they’re assured they have fictitious and usable data.
So how do we achieve this? From the dSource we create a VDB where the masking is performed and use hooks to run a script to do all the account and password stuff. This can be fully automated. This VDB or a child copy of the VDB then becomes our template source. We then create another VDB from that one which becomes the container source. To re-iterate, the template source is a VDB and the container source is a VDB.
Why not make the dSource the template source I hear you ask? Well you can if your masking specification is just one job. However due to limitations of how we can assign masking jobs to VDBs through the virtualisation engine, if we have more than one job we must trigger the masking jobs in some other way. And to be sure unmasked data never reaches the container source it is safer to perform the masking in another VDB first.
Container Refresh
With this configuration, whenever the dev performs a refresh they will get an exact copy of the masked VDB parent in the template. We schedule refreshes of the template masked source from the dSource depending on how often fresh production data is required. And all this can be achieved simply through the use of the Delphix GUIs. If we also utilise the API we have more options for control and usability such as creating bookmarks after each template source refresh providing the end user the ability to switch between date versioned copies of the data without having to bookmark their containers first.
(It’s also worth mentioning here that for dev/test use cases the bookmark sharing feature can make the development lifecycle super simple. For example, the dev can code their new feature and create a shared bookmark that the tester can use to refresh their container with, providing an exact copy of the devs container to test with. But for this feature to be available the containers must be part of the same template.)
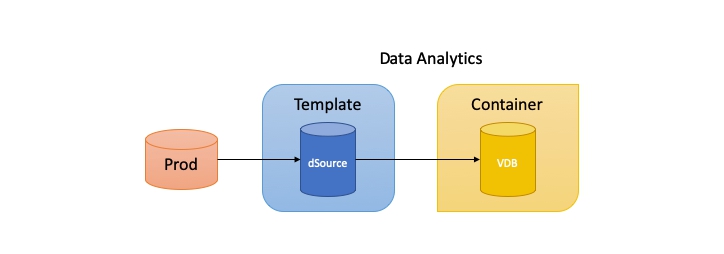
Data Analytics
(To get my point across I’m going to assume the data analysts are allowed to see untouched real production data. In the real world this may not strictly be true.)
So we need to provide the DA with a VDB that has the most up-to-date data possible. In this case we can add the dSource as the template source and create a VDB from this to serve as the container source. We then must pay particular attention to how we configure the synchronisation of the dSource with its linked production source.
Snapsync
The Delphix Snapsync service runs a process of gathering all the changes made on the source database since the last snapsync and provides us with a single snapshot from which we can provision and refresh VDBs. A snapsync policy is created that schedules when and how often the snapsync runs.
Logsync
The Delphix Logsync service runs separately to Snapsync and gathers changes on the source database as they happen in either real-time (per transaction) or by fetching logs from the source as they are created.
Container Refresh
The data copy received by the DA when they perform a refresh depends on how we’ve configured snapsync and logsync.
If we only have snapsync enabled, the refresh will always be from the last successful snapsync (say nightly at midnight). Often this is perfectly adequate.
If we have logsync enabled for logs only, the refresh will be from the last successful copy of the last log produced by the production source. If, in the case of an Oracle source, we have logs and online redo enabled, the refresh will be from the last captured transaction.
As already mentioned, if we utilise the API we can create bookmarks on the template providing the DA the ability to choose timestamps from which to refresh their container.
It’s All About The Template
In summary, make sure you understand the use-case for which you are configuring Self-Service and specifically, what kind of data the end user needs and how often.
If you configure the template and container incorrectly your only recourse is to delete it and start again. As always, avoid rework and understand the requirements thoroughly first.
Update
Long Container Refresh Times
A recent post over on the Delphix Community discussed the often unknown underlying process of VDB creations and refreshes, specifically the process Delphix goes through when performing these actions on an Oracle VDB. The process isn’t unique to Delphix but is quite normal when cloning an Oracle database whether physical or virtual.
Snapsync Vs Logsync
A snapsync of an Oracle dSource is essentially an incremental backup. As with physical incremental backups recovery is a process of applying the incremental to the full backup and recovering with a minimum amount of archive logs to make the database consistent. This is the quickest possible restore/recover time of an online backup.
Logsync on an Oracle dSource collects archive logs. With a physical backup of archive logs, if we want to recover to the current point in time the process is to apply any incrementals to the full backup (as above) then recover every archive log since the last incremental.
I’ve seen multi-terabyte Oracle databases that generate huge amounts of redo (over a 1TB per day) so recovery can take a long time in this scenario. It’s no different with Delphix.
Remember, as discussed, if we’re using logsync on our dSource, which is the source for our template, then when the end user refreshes their container they will receive a current copy of the production source. Delphix will use the last snapsync as the base for the copy and apply every archive log (from logsync) to bring it up to date.
If you see refreshes of Oracle VDBs taking a long time then have a look at the alert log of the VDB and you will more than likely see a ton of archive logs being applied:
Completed: ALTER DATABASE MOUNT
ALTER DATABASE REGISTER PHYSICAL LOGFILE '/mnt/provision/mdevdb/source-archive/arch_1_579_967478511.log'
There are 1 logfiles specified.
ALTER DATABASE REGISTER [PHYSICAL] LOGFILE
Completed: ALTER DATABASE REGISTER PHYSICAL LOGFILE '/mnt/provision/mdevdb/source-archive/arch_1_579_967478511.log'
ALTER DATABASE REGISTER PHYSICAL LOGFILE '/mnt/provision/mdevdb/source-archive/arch_1_580_967478511.log'
There are 1 logfiles specified.
ALTER DATABASE REGISTER [PHYSICAL] LOGFILE
Completed: ALTER DATABASE REGISTER PHYSICAL LOGFILE '/mnt/provision/mdevdb/source-archive/arch_1_580_967478511.log'
...
...
alter database recover automatic database until change 797585 using backup controlfile
Media Recovery Start
Serial Media Recovery started
Media Recovery Log /mnt/provision/mdevdb/source-archive/arch_1_579_967478511.log
Media Recovery Log /mnt/provision/mdevdb/source-archive/arch_1_580_967478511.log
...
...
Incomplete Recovery applied until change 797585
Media Recovery Complete (mdevdb)
To overcome this you simply need to perform more frequent snapsyncs.

Matt is a technology consultant with over 20 years experience helping organisations around the world achieve data success using proven and emerging technologies. He is the Principal Consultant and Head Trainer at Kuzo Data.
Connect with Matt on LinkedIn.