
The process of data masking by its very nature can be a lengthy operation – by this I mean the actual read, transform, update process performed by the masking tool. The time taken from start to finish is directly proportionate to the quantity and complexity of data to be masked.
No two datasets are the same. We have different data store technologies, different schema designs, different ratios of sensitive data contained in the data store. I am often asked how long the masking process will take for a given database before I’ve even seen it! There is no rule of thumb here. The only way we can give a useful estimate is by creating, running and timing the actual masking job(s) themselves.
What we can do though, and we must do, is design our masking configurations/jobs with maximum performance in mind. Performance tuning is often an after thought that inevitably forces rework whereas if we work from the outset with performance in mind we can ensure time and effort is kept to a minimum and most importantly the process runtime is too.
Let’s explore the key areas that affect performance in a typical Delphix data masking enterprise implementation.
We will assume the infrastructure has been deployed according to best practice and provides a performant back bone to work with. We can then break down a Delphix masking pipeline into three main parts when considering performance:
- Database tuning parameters
- Masking specification design
- Engine deployment and tuning parameters
Database Tuning Parameters

Before even logging into the Delphix masking engine we need to make sure our databases are configured for maximum performance. The ultimate aim is to get the best read and write rates possible.
Firstly decide whether this will be in-place or on-the-fly masking. If the latter then we configure the source for selects and the target for inserts. For the former, we only have one database so configure it for both selects and updates (or inserts if we use the “bulk insert” feature in the masking engine).
How we configure our datasets for maximum performance depends on the technology used and I can’t cover all of them here so let’s look at three of the most common enterprise databases.
Oracle
- Switch off archive Logging
- Use automatic memory management and ensure enough is allocated
- Increase undo space and retention to accommodate large tables (for in-place masking)
- Change PCTFREE to 40-50 (this may not be achievable)
SQL Server
- Set the database to Simple Recovery Model
- Use the maximum memory available on the server
SAP ASE
- Use no_recovery durability level
- Combine with setting the sp_dboption ‘trunc log on chkpt’ and ‘select into/bulkcopy/pllsort’ to true
- set DML_Logging to minimal for large tables
Masking specification design

When we create a Delphix masking specification one of the first things to do is create Rule Sets, which are a collection of tables we want to mask. If we blindly do this without thinking about performance we will create a single rule set that contains every table to be masked. However, rule sets are what we create masking jobs against and it’s a one-to-one relationship.
Let’s fast forward in the process a bit and think about masking jobs. A Delphix masking job can be configured with a number of streams, which equate to the number of tables in the ruleset to run concurrently. OK I’m now introducing parallelism so let’s talk about that.
Parallelism
As with almost all computing, parallelism is a fundamental way of improving performance and it’s no different here. In an ideal world, if we have 100 tables in a database to mask, we would run 100 parallel processes to mask each table concurrently. If it take 600 seconds to mask each table, masking in serial will take 100 * 600 = 16 hrs 40 mins. In our ideal parallel world it will take 10 minutes!
Now obviously in the real world these numbers won’t stack up but the aim here is to use all the compute power available by parallelising the process as much as possible. Streams can help us achieve that but we have no control over how the parallelism is played out in the job. We may have a few large tables with lots of columns to mask, a few large tables with one column to mask and many small tables.
Different table structures and quantities of data within them have different consequences on the source/target database. We could easily overwhelm the database and cause an error.
Concurrent Jobs
Therefore we should implement many jobs each with its own ruleset (set of tables) that minimise the impact on the database and then either a) use multiple streams in each job and run one job after another or b) run each job concurrently with a single stream. This way we can control which tables are masked concurrently and therefore control resource consumption.
Again there’s no rule of thumb here so we must consider all factors when designing our masking specification.
Algorithms
The masking process is made up of four phases:
Startup
Read
Transform
Update
The startup phase is affected by the algorithms we choose, particularly Secure Lookup and Mapping algorithms. Values from these algorithms are loaded into memory during the startup phase so try to use as smaller a number of values as necessary to keep the load time to a minimum.
Engine Deployment and Tuning Parameters
Distributed Execution
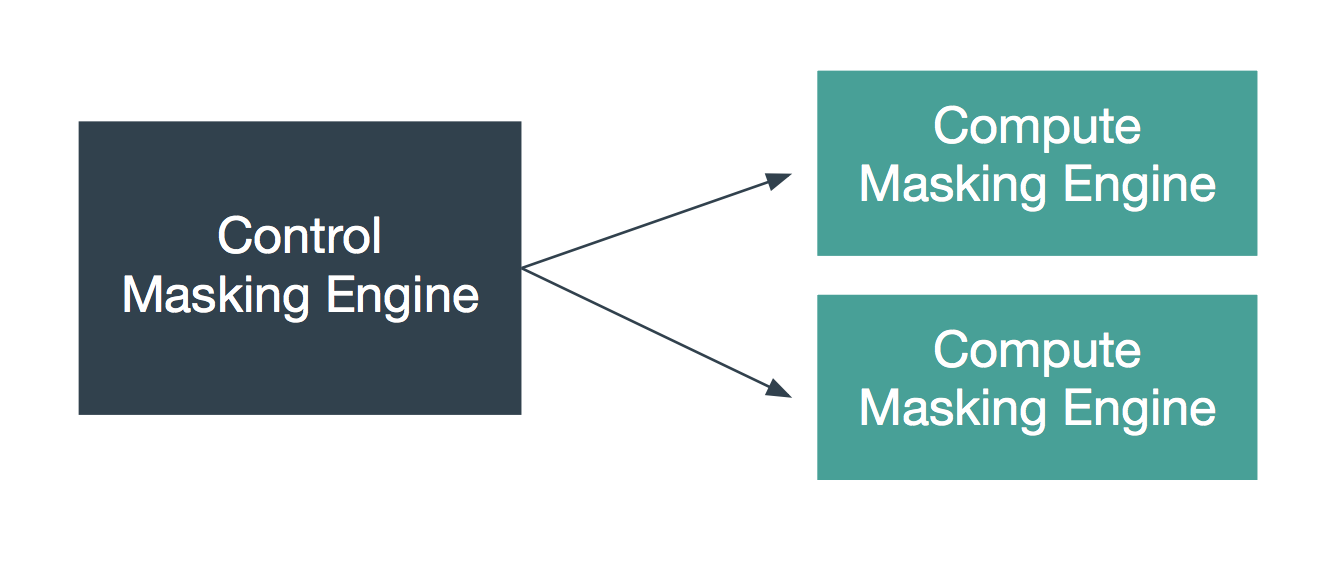
In version 5.2 of the Dynamic Data Platform Delphix introduced the concept of distributed execution of masking jobs amongst many masking engines. It achieved this by creating “syncable objects” – external representations of objects within the Delphix Masking Engine that can be exported from one engine and imported into another.
This allows us to distribute the masking workload to multiple engines, which for large complex systems can reduce the runtime of the masking process considerably. This subject warrants a blog post on its own but in short, if your single engine implementation of masking pushes the resource limit of the engine then consider splitting the workload across more engines. Check out the official docs here.
Job Tuning Parameters
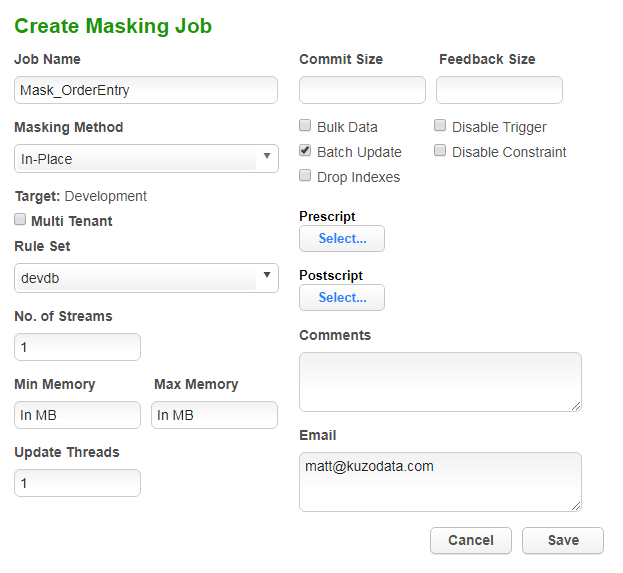
Masking jobs have a number of parameters we can tweak to get optimum reliability and performance.
- No. of Streams – number of tables to run concurrently
- Min Max Memory – amount of engine memory to use
- Update Threads – use parallel threads to update
- Commit Size – number of rows to process before issuing a commit to the database
- Bulk Data – for in-place masking, use inserts instead of updates
- Batch Update – execute statements in batches
- Drop Index – drop index then recreate after masking has completed
Again, there is no best practice or rule of thumb for each of the tuning parameters and you can find that changing a parameter can in fact adversely affect performance. If your tables have indexes then the one that can often yield the most improvement is drop index.
Final Thought
Creating a Delphix masking pipeline in it’s simplest form may well be ok for your dataset and requirements – a small single database with one rule set and job running serially with default database and masking job parameters takes say 30 mins. We need a refresh once a week. That will do nicely.
But in most enterprises the pipeline involves numerous multi-terabyte inter-linked databases with billions of rows to mask – that same configuration ain’t gonna cut it!
Consider performance every step of the way.
For a more detailed look at Delphix data masking performance check out their KB Article.

Matt is a technology consultant with over 20 years experience helping organisations around the world achieve data success using proven and emerging technologies. He is the Principal Consultant and Head Trainer at Kuzo Data.
Connect with Matt on LinkedIn.